From 2008.igem.org
Perl
The first major thing the software team worked on was finding a way to expand the database for EvoGEM. As of that moment, EvoGEM only had a small database of BioBrick parts, and all of those parts were added manually. Since the iGEM registry consisted of hundreds of parts, manually adding parts would not be practical. In addition, these parts were needed so that more sophisticated tests could made with EvoGEM. Also, we wanted to have some way of comparing the parts that were retrieved. If they were enzymes, what reactions were they catalyzing? If they were molecules, what were the molecular structures or other synonyms for these compounds? The answers to these questions would allow EvoGEM to learn and distinguish different molecules and compounds better. How do we accomplish this, though? By creating a Perl script!
Perl is a programming language that is powerful in text processing facilities. Since it uses string matching so well, it is an ideal language for searching text and manipulating text files, which is exactly what is needed for retrieving and expanding the local database for EvoGEM.
UniProt
If there is a protein that is existent in one of the parts retrieved from the iGEM database, that result is sent to UniProt. UniProt is a large database of proteins and enzymes. This database can be used and queried by using something known as the Blast algorithm, which is a very powerful tool. When inputting the DNA or amino acid sequence, UniProt will give results that are closest to the initial search. Besides giving the name of the protein searched, UniProt will give the further products and reactants involved in this protein. All this information can be used for further use for EvoGEM and is stored in a local database. After going to the registry for the information of the parts. Go here [http://www.uniprot.com Uniprot] to see this database.
ChemSpider
After results are gone through UniProt, if there are further molecules that are involved in the reaction that are not proteins, the search goes to ChemSpider. This large database is much like UniProt except that it is for chemistry. Searching and querying in ChemSpider is quite simple as things can be queried using synonyms of molecules. This makes it a very useful tool. After a molecule is queried, ChemSpider will produce information about the molecule such as synonyms and SMILES, which is a simplified molecular input line entry specification. As useful as this information can be, the reason for coming for this database is to get something that is machine readable and can be used for comparisons of metabolic pathways. What is this machine readable format? This machine readable format is known as the IUPAC International Chemical Identifier (InChI). This InChi is a unique "fingerprint" of the molecule that is not ambiguous like SMILES and is supplied only by IUPAC. An example of an InChi would look like this:
1/C6H8O6/c7-1-2(8)5-3(9)4(10)6(11)12-5/h2,5,7-8,10-11H,1H2/t2-,5+/m0/s1
To see this database, go here: [http://www.chemspider.com ChemSpider]
The Algorithm
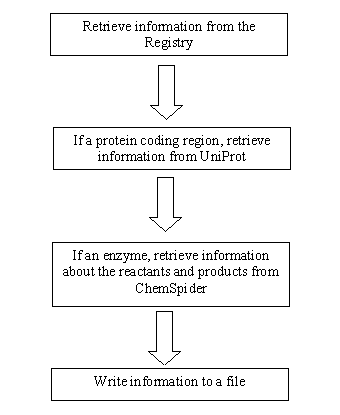
Figure 2.0 - Data Retrieval Flow Chart
The Perl script’s algorithm works in the following manner. First, it goes to the iGEM registry and takes one of the parts, where it records its name, type, and sequence. Then, if the part happens to be a protein, the information would be sent to Uniprot, where it will go through the Blast algorithm. From there, the names of reactants and products are extracted and stored into a file for the local database of EvoGEM. Afterwards, if there are molecules involved in the reaction of proteins, these compounds are searched in ChemSpider. There, more information such as the InChi is also stored into the local database for further use. (See Figure 2.0) Consequently, we now have a large database ready for use for EvoGEM.
Navigation
 "
"



