|
Method & Algorithm : ƒ2
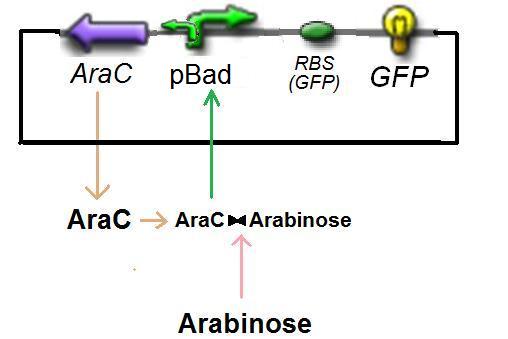 Specific Plasmid Characterisation for ƒ2 According to the characterization plasmid (see right) and to our modeling, in the exponential phase of growth, at the steady state, the experiment would give us
and at steady-state and in the exponential phase of growth, we expect :
we use this analytical expression to determine the parameters :
↓ Table of Values ↑
| param
| signification
| unit
| value
| comments
|
| (fluorescence)
| value of the observed fluorescence
| au
|
| need for 20 measures with well choosen [arab]i
|
| conversion
| conversion ratio between
fluorescence and concentration
↓ gives ↓
| nM.au-1
| (1/79.429)
|
|
| [GFP]
| GFP concentration at steady-state
| nM
|
|
|
| γGFP
| dilution-degradation rate
of GFP(mut3b)
↓ gives ↓
| min-1
| 0.0198
| Only Dilution
Time Cell Disvision : 35 min.
|
| ƒ2
| activity of
pBad with RBS E0032
| nM.min-1
|
|
|
| param
| signification
corresponding parameters in the equations
| unit
| value
| comments
|
| βbad
| total transcription rate of
pBad with RBS E0032
not in the Core System
| nM.min-1
|
|
|
| (γ Kbad/const.expr(pBad))
| activation constant of pBad
not in the Core System
| nM
|
|
|
| nbad
| complexation order of pBad
not in the Core System
| no dimension
|
| The literature [?] gives nbad =
|
| Kara
| complexation constant Arabinose><AraC
not in the Core System
| nM
|
| The literature [?] gives Kara =
|
| nara
| complexation order Arabinose><AraC
not in the Core System
| no dimension
|
| The literature [?] gives nara =
|
|
↓ Algorithms ↑
|
find_ƒ2
function optimal_parameters = find_f2(X_data, Y_data, initial_parameters)
function output = expr_pBad(parameters, X_data)
for k = 1:length(X_data)
output(k) = parameters(1) * ( hill( ...
(hill(X_data(k), parameters(4), parameters(5))), parameters(2), parameters(3)) );
end
end
options=optimset('LevenbergMarquardt','on','TolX',1e-10,'MaxFunEvals',1e10,'TolFun',1e-10,'MaxIter',1e4);
optimal_parameters = lsqcurvefit( @(parameters, X_data) expr_pBad(parameters, X_data), ...
initial_parameters, X_data, Y_data, 1/10*initial_parameters, 10*initial_parameters, options );
end
Inv_ƒ2
function quant_ara = Inv_f2(inducer_quantity)
function equa = F(x)
equa = f2( x ) - inducer_quantity;
end
options=optimset('LevenbergMarquardt','on','TolX',1e-10,'MaxFunEvals',1e10,'TolFun',1e-10,'MaxIter',1e4);
quant_ara = fsolve(F,1,options);
end
|
That will give us directly ƒ2([arab])
<Back - to "Implementation" |
<Back - to "Protocol Of Characterization" |
|
 "
"



