|
Home
The Team
Project Report
Parts
Modeling
Notebook
Safety
CoLABoration
|
_cloning strategy
Introduction
To form different types of synthetic receptor constructs a modular building set was used. We designed the genes of two parts coding for extracellular binding proteins (anti NIP scFv, anti-Flu Lipocalin) and four different components of an intracellular signal transduction reporter protein (Cerulean CFP, Venus YFP, β-Lactamase, and Luciferase). These reporters were designed as split-proteins to achieve activaton only when two receptors come together and form a cluster. With this strategy, a signal is only given by two binding-molecules that are next to each other as it is realized in the DNA-origami structure or the NIP and Fluorescein-coupled BSA.
The whole receptor construct consists out of (i) a signal peptide, (ii) an extracellular receptor domain, (iii) a GGGS-linker followed by (iv) a transmembrane region and (v) an intracellular split-reporter-protein. The signal peptide sequence equal to that of human EGF-receptor erbb1 ensures the transport of the protein construct to the cytoplasma membrane. A GGGS-linker is necessary to create a distance between membrane and the recognition-site to tower cell surface structures as glycoproteins and glycolipids. The sequence of the transmembrane region is taken from the EGF-receptor erbb1 as well. The C-terminal split-parts of Venus-YFP and Cerulean CFP were not directly fused to the transmembrane region. To get a little bit more flexibility in binding to the N-terminal part, a split fluorophor-linker was assembled in between.
Almost all parts were ordered by gene synthesis in a pMA-vector system that is adapted for cloning BioBrick parts. The constructs were designed according to BioBrick 3.0 standard with the modification for fusion-proteins proposed by the iGEM Freiburg Team 2007 (FreiGEM07_report_fusion_part). Keeping the standard iGEM prefix and suffix, the restriction sites NgoMIV and AgeI were added to create functional fusions without stop-codons.
All possible variations of the receptor constructs were fused together in the pMA-vector and afterwards inserted into a transfection vector. The transfection vector is a BioBrick 2006 part from the Ljubljana, Slovenia team (BBa_J52017) and includes a kanamycin and ampicillin resistance cassette. There is a pMB1 Ori and the multiple cloning site consist of the BioBrick Prefix and Suffix restriction enzymes (Prefix: EcoRI, NotI, XbaI/ Suffix: SpeI, NotI, PstI) followed by an eukaryotic terminator sequence. To achieve a strong expression, a constitutive promoter construct was needed. Because of this, the Cytomegalovirus [CMV] promotor was amplified by PCR using the BioBrick part BBa_J52038 from the 2006 Ljubljana, Slovenia team as well and primers mentioned below. The forward primer bound in the iGEM-prefix, while the reverse primer bound at the end of the CMV-coding region. The reverse primer also contained an overhang to get the iGEM-suffix directly to the end of the promoter sequence which later allowed the cloning into the transfection vector. The CMV promoter was cloned into the vector by using the EcoRI and PstI restriction sites. To test the expression activity of the vector with the CMV promoter, the gene of the yellow fluorescent protein [YFP] was cloned downstream of the promoter region by using XbaI, PstI restriction enzymes for the YFP insert and SpeI, PstI for the vector to open the Biobrick suffix. The transfection of the resulting plasmid into 293T cells shows full functionality.
An overview about the cloning is given in table 1
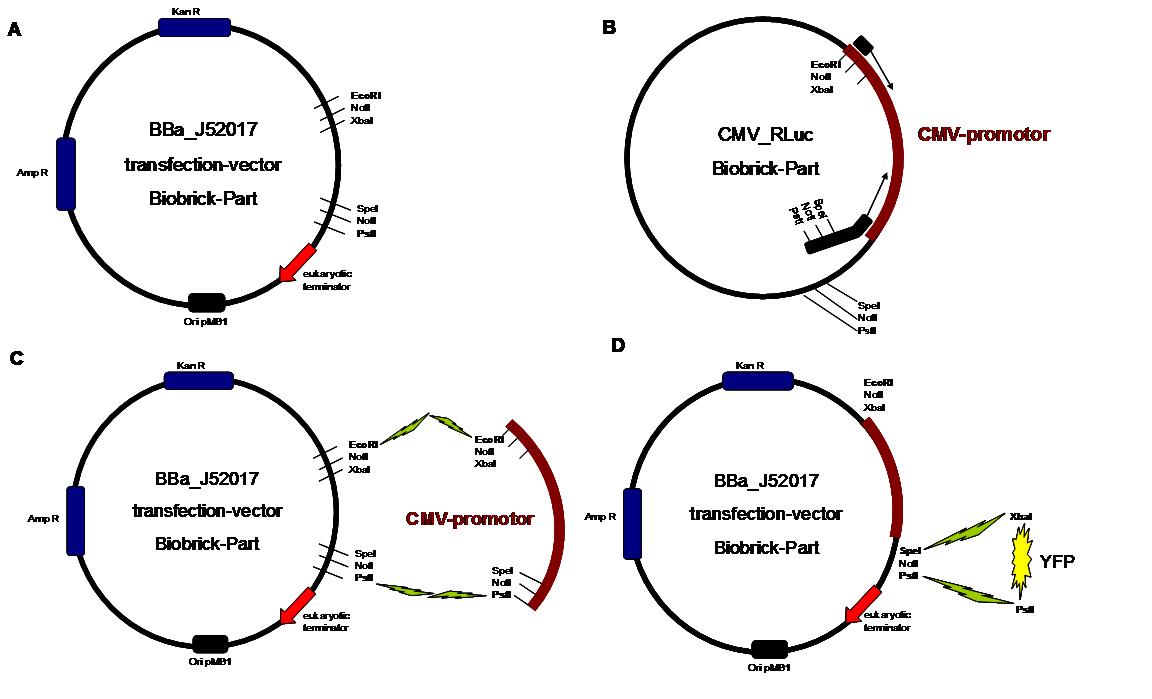
Figure 1_cloning strategy
. A
shows the Biobrick part BBa_J52017. The transfection vector
for eukaryotic cell systems has an ampicillin and a kanamycin
resistance cassette. The multiple cloning site contains the Biobrick
standard restriction sites EcoRI, NotI, XbaI, SpeI, NotI, PstI followed
by a eukaryotic terminator sequence. B The
CMV promotor fragment was obtained by PCR from the Biobrick BBa-J52038
template. C
The PCR product was cloned into the transfection vector by EcoRI and
PstI to get a final eukaryotic transfection system. D To
test the efficiency of expression, a gene fragment coding for the yellow
fluorescent protein was cloned into the vector downstream of the CMV Promotor.
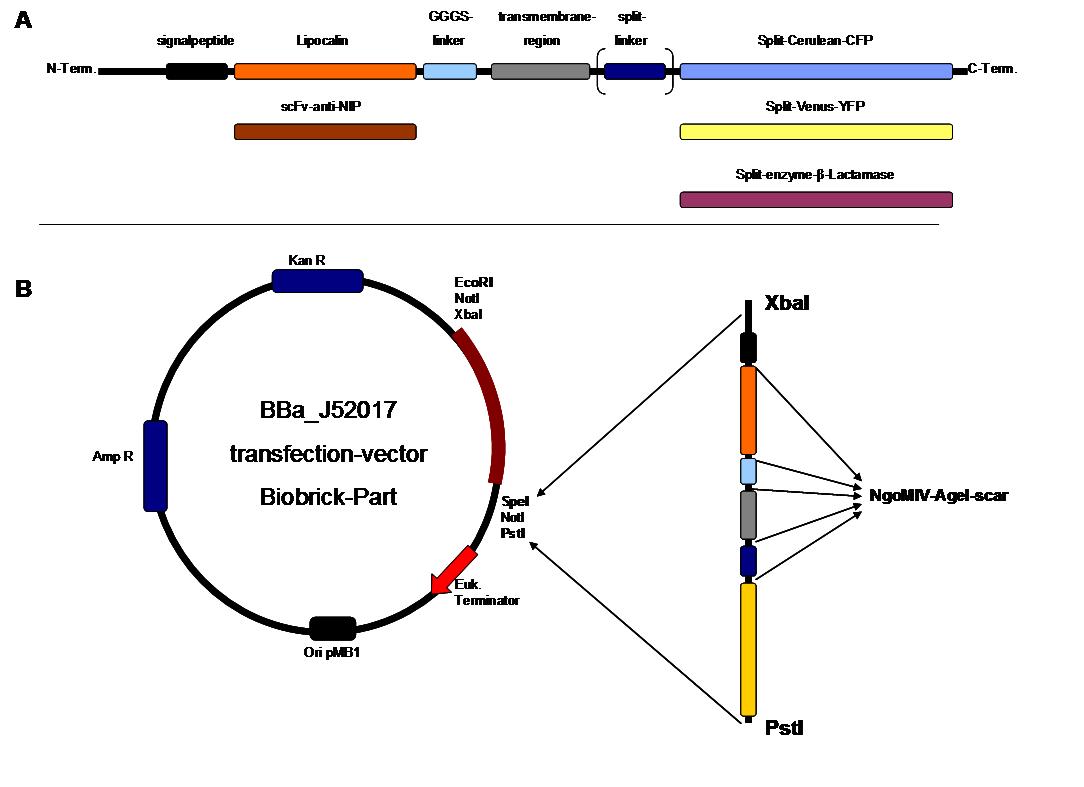
Figure 2_cloning strategy
. A
figure 2 A gives an overview about the cloning constructs.
The N-terminal signal peptide ensures protein transport to the
cytoplasma membrane. Lipocalin and the scFv-anti-NIP are the
extracytoplasmatic parts of the construct to mediate signal transduction
into the cell. The GGGS-Linker keeps a distance to the
transmembrane region to overcome surface structures of the cell and to
avoid a total inflexibility. The split fluorophor linker is only necessary
for the C-terminal split parts of Cerulean-CFP and
Venus-YFP. The split enzymes β-Lactamase and Luciferase
and the split-fluorophors CFP and YFP are the cytoplasmatic parts of
the constructs. If there is a clustering of this synthetic
receptor-system caused by the corresponding binding parts of Lipocalin
and scFv-anti-NIP, the split parts come together to create a functional
protein, which allows detection.
B The
different constructions described in figure 2.A were cloned into the
transfection vector system by using the restriction sites XbaI and PstI
to ensure a functional ATG-start codon which is part of the XbaI
recognition-sequence in the iGEM-prefix.
Table1_cloning strategy overview about
the cloning steps to create the different types of synthetic
receptors. To get further information about the composite parts see
https://2008.igem.org/Team:Freiburg/Parts
|
Step 1
|
Vector
digestion: EcoRI + PstI
|
Insert
digestion: EcoRI + PstI
|
|
|
BBa-J52017
|
_CMV-promotor
|
|
Step
2
|
Vector
digestion: AgeI+SpeI
|
Insert
digestion: NgoMIV+SpeI
|
|
|
pMA-BBFR
_ SPLIT-Linker
|
C-YFP
|
|
|
C-CFP
|
|
Step
3
|
Vector
digestion: AgeI+SpeI
|
Insert
digestion: NgoMIV+SpeI
|
|
|
pMA-BBFR
_egfR-Tm
|
_ N-β-Lactamase
|
|
|
_ C-β-Lactamase
|
|
|
_ SPLIT-Linker_ C-YFP
|
|
|
_ N-YFP
|
|
|
_ SPLIT-Linker_ C-CFP
|
|
|
_ N-CFP
|
|
|
_ BB058 (Luciferase)
|
|
|
_ BB057 (Luciferase)
|
|
Step
4
|
Vector
digestion: AgeI+SpeI
|
Insert
digestion: NgoMIV+SpeI
|
|
|
pMA-BBFR
_SP
|
_scFv-anti-NIP
|
|
|
_ Lipocalin
|
|
Step
5
|
Vector
digestion: AgeI+SpeI
|
Insert
digestion: NgoMIV+SpeI
|
|
|
pMA-BBFR
_SP_ scFv-anti-NIP
and
pMA-BBFR-+SP_ Lipocalin
|
_GGGS-linker (produced by Klenow fill in)
|
|
Step
6
|
Vector
digestion: AgeI+SpeI
|
Insert
digestion: NgoMIV+SpeI
|
|
|
pMA-BBFR
_SP_ scFv-anti-NIP _ GGGS-Li
and
pMA-BBFR
_ SP_ Lipocalin _
GGGS-Li
|
_
egfR-Tm _ N-β-Lactamase
|
|
|
_
egfR-Tm _ C-β-Lactamase
|
|
|
_
egfR-Tm _ SPLIT-Linker_ C-YFP
|
|
|
_
egfR-Tm _ N-YFP
|
|
|
_
egfR-Tm _ SPLIT-Linker_ C-CFP
|
|
|
_
egfR-Tm _ N-CFP
|
|
|
_
egfR-Tm _ BB058 (Luciferase)
|
|
|
_
egfR-Tm _ BB057 (Luciferase)
|
|
Step
7
|
Vector
digestion:
SpeI + PstI
|
Insert
digestion: XbaI + PstI
|
|
|
BBa-J52017_CMV
|
_SP_ scFv-anti-NIP_GGGS-Li_egfR-Tm_N-β-Lactamase
|
|
|
_ SP_ scFv-anti-NI _GGGS-Li_ egfR-Tm_C-β-Lactamase
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li_
egfR-Tm_SPLIT-Linker_C-YFP
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li_ egfR-Tm_N-YFP
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li_
egfR-Tm_SPLIT-Linker_C-CFP
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li_ egfR-Tm_N-CFP
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li _ egfR-Tm_BB058 (Luciferase)
|
|
|
_ SP_ scFv-anti-NIP_GGGS-Li _ egfR-Tm_BB057 (Luciferase)
|
|
|
_ SP_ Lipocalin _GGGS-Li_ egfR-Tm_N-β-Lactamase
|
|
|
_ SP_ Lipocalin _GGGS-Li_ egfR-Tm_C-β-Lactamase
|
|
|
_ SP_ Lipocalin _GGGS-Li_
egfR-Tm_SPLIT-Linker_ C-YFP
|
|
|
_ SP_ Lipocalin _GGGS-Li_
egfR-Tm_N-YFP
|
|
|
_ SP_ Lipocalin _GGGS-Li_
egfR-Tm_SPLIT-Linker_ C-CFP
|
|
|
_ SP_ Lipocalin _GGGS-Li_
egfR-Tm_N-CFP
|
|
|
_ SP_ Lipocalin _GGGS-Li__ egfR-Tm _ BB058 (Luciferase)
|
|
|
_ SP_ Lipocalin _GGGS-Li__ egfR-Tm _ BB057 (Luciferase)
|
Methods
The cloning was started with a preparative digestion of the DNA-Plasmids. To clone fusion parts the vector constructs were digested with AgeI and PstI to open the Biobrick suffix. The inserts were digested with NgoMIV and PstI. For cloning into the transfection-vector the enzymes SpeI and PstI were used for vector and XbaI, PstI for insert to keep up the ATG-start codon in the XbaI restriction site of the biobrick suffix. All restriction-enzymes were ordered from New England Biolabs. After digestion the DNA-fragments were separated on a 1% agarose gel. The DNA-band of interest was isolated and purified with the QIAGEN QIAquick Gel Extraction Kit. For the ligation a 3 molar excess of the insert was put together with the vector-fragment and ligated with a Quick ligase (New England Biolabs). After half an our at room temperature the DNA was transformed to chemical competent E.coli strain XL1 cells, plated on 2YT-agar-plates and incubated at 37°C over night. After picking clones and growing in 5ml LB-medium, the plasmid DNA was isolated by QIAGEN QIAprep Spin Miniprep Kit. A test digestion was prepared with about 0,5µg Plasmid DNA and NotI restriction enzyme to isolate the fusion-protein from the vector and to control if the expected bands were obtained. After a positive result the clones were sent to GATC-Biotech for sequencing.
The GGGS-Linker was produced by Klenow -fill-in-PCR. Two primers were designed align to each other at 60°C and filled to a complete double-strand by Klenow Polymerase fragment.
Digestion Protocol
- about 2µg Plasmid-Prep in 20µl
- 2 µl NEB Buffer 10x
- 1 µl NEB enzyme 1 (NgoMIV, AgeI, XbaI, EcoRI)
- 1 µl NEB enzyme 2 (PstI, SpeI)
- 0.2µl BSA 100x
Ligation
- 10µl volume of vector and insert DNA (about 50ng vector-DNA)
- 1 µl DNA Quick Ligase (New England Biolabs)
- 10 µl Quick Ligase Buffer
Analytic digestion
- about 0.5 µg Plasmid-DNA in 5µl
- 5µl H2O
- 0.5 µl NotI
- 1µl NEB-Buffer
- 0.1 µl BSA
Transformation
- Competent cells (100µl) werde defrosted on ice
- 10µl of the ligation was added
- DNA and cells werde mixed softly
- Incubation on ice for 20-30 min
- Heat shock at 42°C for 40 sek
- cells were cooled down on ice for 5-10 min
- 900µl sterile 2YT Medium was added
- Incubation at 37°C for 60-70 min (shaker)
- cells werde plated on 2YT-agar-plates with antibiotics
Klenow fill in reaction
- 25pmol forward primer
- 25pmol reverse primer
- 0.5 µl Klenow-fragment without exonuclease activity (Fermentas)
- 2µl Klenow Buffer
- 1µl dNTPs
- Add H2O to a volume of 20µl
program: 94°C for 3min, cool down to 37°C, adition of klenow enzyme, 37°C for 1 hour
Results
All composite parts were succesfully cloned and controlled by sequencing and transfection as well (Freiburg Transfection and Synthetic Receptor)
Biobrick fusion protein
The present BioBrick prefix and suffix rules are not compatible with modular protein design. Thus as in 2007, we proposed an extension of the present standard for fusion proteins in which two restriction sites are added in frame adjacent to the coding sequence. The basic parts and as well all composite parts follow this strategy.
To get further information see FreiGEM07_report_fusion_part
Cloned parts
The cloning parts scFv-anti-NIP, lipocalin-FluA, Split-Venus-N-YFP, Split-Venus-C-YFP, Cerulean-N-CFP and Cerulean-C-CFP were obtained by genesynthesis and ordered by the GENEART company. The β-Lactamase fragments were adopted from genesynthesis GENEART order in 2007. The erbb1-transmembrane, Split-Fluorophor-Linker and the erbb1-signalpeptide were synthesized by ATG:biosynthetics. The CMV promoter cloning part was produced by PCR with the template J52038 using the CMV_RLuc_Forward-primer and CMV_RLuc_Reverse-primer. To synthesize the GGGS-linker a Klenow-fill-in-reaction was performed by using Klenow-fragment without exonuclease activity and GGGS-forward and reverse primer.
CMV-Promotor-PCR BBa_K157040
CMV_RLuc_Forward-primer: TCGCTAAGGA TGATTTCTGG AA
CMV_RLuc_Reverse-primer: AACGATCCTG CAGCGGCCGC TACTAGTAAT TTCGATAAGC CAGTAAGCAG
GGGS-Linker (primer-fill-in)
AA sequence:
GGGSGGGSGG GSGGG
gene sequence:
GGAGGAGGTG GTTCAGGTGG TGGTGGTAGT GGAGGAGGAG GATCC
GGGS_Forward-primer: ATTATATTGA ATTCGCGGCC GCTTCTAGAt gGCCGGCGGA GGAGGTGGTT CAGGTGGTGG TGGTAGTGGA
GGGS_Reverse-primer:
TTATATTTCT GCAGCGGCCG CTACTAGTAT TAACCGGTGG ATCCTCCTCC TCCACTACCA CCACCACCT
GGGS-linker (pMA) BBa_K157013
AA sequence:
GGGSGGGSGG GSGGG
gene sequence:
GGTGGAGGAG GTTCTGGAGG CGGTGGAAGT GGTGGCGGAG GTAGC
Erbb1-transmembraneregion BBa_K157002
IAA sequence:
ATGMVGALLL LLVVALGIGL FM
gene sequence:
ATAGCTACCG GAATGGTGGG TGCACTTTTG CTCCTTTTGG TCGTTGCCCT GGGGATAGGA CTCTTTATG
Signalpeptide BBa_K157001
AA sequence:
MRPSGTAGAA LLALLAALCP ASRA
gene sequence:
ATGAGACCAT CTGGTACTGC TGGAGCCGCA TTGCTGGCAC TTTTGGCTGC GCTGTGCCCT GCAAGCAGAG CA
Split-Fluo-Linker BBa_K157009
AA sequence:
RPACKIPNDL KQKVMNH
gene sequence:
CGACCAGCCT GTAAGATTCC AAATGACCTG AAGCAGAAAG TTATGAATCA C
Sc-Fv anti NIP BBa_K157003
AA sequence:
QVQLQQPGAE LVKPGASVKL SCKASGYTFT SYWMHWVKQR PGRGLEWIGR IDPNSGGTKY NEKFKSKATL TVDKPSSTAY MQLSSLTSED SAVYYCARYD YYGGSYFDYW GQGTTVTVSS GGGGSGGGGS GGGGSQAVVT QESALTTSPG ETVTLTCRSS TGAVTTSNYA NWVQEKPDHL FTGLIGGTNN RAPGVPARFS GSLIGDKAAL TITGAQTEDE AIYFCALWYS NHWVFGGGTK LTVLG
gene sequence:
CAGGTGCAGC TCCAGCAGCC CGGAGCCGAA CTGGTGAAGC CAGGCGCCAG CGTGAAGCTG TCCTGCAAGG CCAGCGGCTA CACCTTCACC AGCTACTGGA TGCACTGGGT GAAACAGAGG CCCGGCAGAG GCCTGGAATG GATCGGCCGG ATCGACCCCA ACAGCGGCGG CACCAAGTAC AACGAGAAGT TCAAGAGCAA GGCCACCCTG ACCGTGGACA AGCCCAGCAG CACCGCCTAC ATGCAGCTGT CCAGCCTGAC CAGCGAGGAC AGCGCCGTGT ACTACTGCGC CAGATACGAC TACTACGGCG GCAGCTACTT CGACTACTGG GGCCAGGGCA CCACCGTGAC CGTGTCCTCT GGGGGAGGGG GCTCAGGAGG AGGAGGAAGC GGGGGAGGGG GCAGCCAGGC CGTGGTGACC CAGGAAAGCG CCCTGACCAC TCCCCTGGCG GACAGTGACC TGACCTGCCG TCCTCTACAG GCGCCGTGAC CACAAGCAAC TACGCCAACT GGGTGCAGGA AAAGCCCGAC CACCTGTTCA CCGGCCTGAT CGGCGGCACA AACAACAGAG CCCCTGGCGT GCCCGCTAGA TTCAGCGGCA GCCTGATCGG GGACAAGGCC GCCCTGACAA TCACAGGCGC CCAGACCGAG GACGAGGCCA TCTACTTTTG CGCCCTGTGG TACAGCAACC ACTGGGTGTT CGGCGGAGGG ACCAAGCTGA CCGTGCTGGG C
Split-Venus-N-YFP BBa_K157008
AA sequence:
MVSKGEELFT GVVPILVELD GDVNGHKFSV SGEGEGDATY GKLTLKLICT TGKLPVPWPT LVTTLYLQCF ARYPDHMKQH DFFKSAMPEG YVQERTIFFK DDGNYKTRAE VKFEGDTLVN RIELKGIDFK EDGNILGHKL EYNYNSHNVY ITADKQ
gene sequence:
ATGGTGTCCA AGGGCGAGGA ACTGTTCACC GGCGTGGTGC CCATCCTGGT GGAGCTGGAC GGCGACGTGA ACGGCCACAA GTTCAGCGTG TCCGGCGAGG GCGAAGGCGA CGCCACCTAC GGCAAGCTGA CCCTGAAGCT GATCTGCACC ACCGGCAAGC TGCCCGTGCC CTGGCCCACC CTGGTGACCA CCCTGTACCT CCAGTGCTTC GCCAGATACC CCGACCACAT GAAGCAGCAC GATTTCTTCA AGAGCGCCAT GCCCGAGGGC TACGTGCAGG AACGGACCAT CTTCTTCAAG GACGACGGCA ACTACAAGAC CAGAGCCGAA GTGAAGTTCG AGGGCGACAC ACTGGTGAAC CGGATCGAGC TGAAGGGCAT CGACTTCAAA GAGGACGGCA ATATCCTGGG CCACAAGCTG GAATACAACT ACAACAGCCA CAACGTGTAC ATCACCGCCG ACAAGCAG
Split-Venus-C-YFP BBa_K157007
AA sequence:
KNGIKANFKI RHNIEDGGVQ LADHYQQNTP IGDGPVLLPD NHYLSYQSKL SKDPNEKRDH MVLLEFVTAA GITHGMDELY K
gene sequence:
AAGAACGGCA TCAAGGCCAA CTTCAAGATC CGGCACAACA TCGAGGACGG CGGCGTGCAG CTGGCCGACC ACTACCAGCA GAACACCCCC ATCGGCGACG GCCCCGTGCT GCTGCCCGAC AACCACTACC TGAGCTACCA GAGCAAGCTG TCCAAGGACC CCAACGAGAA GCGGGACCAC ATGGTGCTGC TGGAATTTGT GACAGCCGCC GGAATCACCC ACGGCATGGA CGAGCTGTAC AAG
Cerulean-N-CFP BBa_K157006
AA sequence:
MSKGEELFTG VVPILVELDG DVNGHKFSVS GEGEGDATYG KLTLKFICTT GKLPVPWPTL VTTLGVQCFA RYPDHMKRHD FFKSAMPEGY VQERTIFFKD DGNYKTRAEV KFEGDTLVNR IELKGIDFKE DGNILGHKLE YNAISDNVYI TADKQ
gene sequence:
ATGAGCAAGG GCGAGGAACT GTTCACCGGC GTGGTGCCCA TCCTGGTGGA GCTGGACGGC GACGTGAACG GCCACAAGTT CAGCGTGTCC GGCGAGGGCG AAGGCGACGC CACCTACGGC AAGCTGACCC TGAAGTTCAT CTGCACCACC GGCAAGCTGC CCGTGCCCTG GCCCACCCTG GTGACCACCC TGGGCGTGCA GTGCTTCGCC AGATACCCCG ACCACATGAA GCGGCACGAT TTCTTCAAGA GCGCCATGCC CGAGGGCTAC GTGCAGGAAC GGACCATCTT CTTCAAGGAC GACGGCAACT ACAAGACCAG AGCCGAAGTG AAGTTCGAGG GCGACACACT GGTGAACCGG ATCGAGCTGA AGGGCATCGA CTTCAAAGAG GACGGCAATA TCCTGGGCCA CAAGCTGGAA TACAACGCCA TCAGCGACAA CGTGTACATC ACCGCCGACA GCAG
Cerulean-C-CFP BBa_K157005
AA sequence:
KNGIKANFKI RHNIEDGSVQ LADHYQQNTP IGDGPVLLPD NHYLSTQSKL SKDPNEKRDH
gene sequence:
MVLLEFVTAA GITLGMDELY KAAGAACGGC ATCAAGGCCA ACTTCAAGAT CCGGCACAAC ATCGAGGATG GCAGCGTGCA GCTGGCCGAT CACTACCAGC AGAACACCCC CATCGGCGAC GGCCCCGTGC TGCTGCCCGA CAACCACTAC CTGAGCACCC AGAGCAAGCT GTCCAAGGAC CCCAACGAGA AGCGGGACCA CATGGTGCTG CTGGAATTTG TGACAGCCGC CGGAATCACC CTGGGCATGG ACGAGCTGTA CAAG
Split beta-Lactamase 1/2 BBa_K157018
AA sequence:
MAGIATGMVG ALLLLLVVAL GIGLFMTGHP ETLAKVKDAE DQLGARVGYI ELDLNSGKIL ESFRPEERFP MMSTFKVLLC GAVLSRIDAGQ EQLGRRIHYS QNDLVEYSPV TEKHLTDGM TVGELCSAAI TMSDNTAANL LLTTIGGPKE LTAFLRNMGDH VTRLDRWEPE LNEAIPNDE RDTTTPVAMAT TLRKLLTGEL LGTG*
gene sequence:
ATGGCCGGCA TAGCTACCGG AATGGTGGGT GCACTTTTGC TCCTTTTGGT CGTTGCCCTG
GGGATAGGAC TCTTTATGAC CGGCCACCCG GAAACCCTGG CCAAAGTGAA AGATGCGGAA GATCAGCTGG GTGCGCGTGT GGGCTATATT GAACTGGATC TGAACAGCGG CAAAATTCTG GAATCTTTTC GTCCGGAAGA ACGTTTTCCG ATGATGAGCA CCTTTAAAGT GCTGCTGTGC
GGTGCGGTTC TGAGCCGTAT TGATGCGGGC CAGGAACAGC TGGGCCGTCG TATTCATTAT AGCCAGAACG ATCTGGTGGA ATATAGCCCG GTGACCGAAA AACATCTGAC CGATGGCATG ACCGTGGGCG AACTGTGCAG CGCGGCGATT ACCATGAGCG ATAACACCGC GGCGAACCTG CTGCTGACCA CCATTGGCGG TCCGAAAGAA CTGACCGCGT TTCTGCGTAA CATGGGCGAT CATGTGACCC GTCTGGATCG TTGGGAACCG GAACTGAACG AAGCGATTCC GAACGATGAA
CGTGATACCA CCACCCCGGT GGCCATGGCG ACCACCCTGC GTAAACTGCT GACCGGCGAA CTGCTGGGCA CCGGTTAA
Split beta-Lactamase 2/2 BBa_K157019
AA sequence:
MAGIATGMVG ALLLLLVVAL GIGLFMTGGT PASRQQLMDW MKADKVAGPL LRSVLPAGWF IADKSGAGER GSRGIIAALG PDGKPSRIVV IYTTGSQATM DELNRQIAEI GASLIKHWTG *
gene sequence:
ATGGCCGGCA TAGCTACCGG AATGGTGGGT GCACTTTTGC TCCTTTTGGT CGTTGCCCTG GGGATAGGAC TCTTTATGAC CGGCGGTACT CCGGCTTCCC GGCAACAATT AATGGACTGG ATGAAAGCGG ATAAAGTTGC AGGACCACTT CTGCGCTCGG TGCTTCCGGC TGGCTGGTTT ATTGCTGATA AATCTGGAGC CGGTGAGCGT GGGTCTCGCG GTATCATTGC AGCACTGGGG CCAGATGGTA AGCCCTCCCG TATCGTAGTT ATCTACACGA CGGGGAGTCA GGCAACTATG GATGAACTGA ATCGTCAGAT CGCTGAGATA GGTGCCTCAC TGATTAAGCA TTGGACCGGT
TAA
Split Luciferase 58 BBa_K157020
AA sequence:
EAIVDIPEIP GFKDLEPMEQ FIAQVDLCVD CTTGCLKGLA NVQCSDLLKK WLPQRCATFA SKIQGQVDKI KGAGGD
gene sequence:
GAAGCGATTG TGGATATTCC GGAAATTCCG GGCTTTAAAG ATCTGGAACC GATGGAACAG TTTATTGCGC AGGTGGATCT GTGCGTGGAT TGCACCACCG GCTGCCTGAA AGGCCTGGCC AACGTGCAGT GCAGCGATCT GCTGAAAAAA TGGCTGCCGC AGCGTTGCGC GACCTTTGCG AGCAAAATTC AGGGCCAGGT GGATAAAATT AAAGGCGCGG GTGGCGAT
Split Luciferase 57 BBa_K157021
AA sequence:
KPTENNEDFN IVAVASNFAT TDLDADRGKL PGKKLPLEVL KEMEANARKA GCTRGCLICL SHIKCTPKMK KFIPGRCHTY EGDKESAQGG IG
gene sequence:
AAACCGACCG AAAACAACGA AGATTTTAAC ATTGTGGCGG TGGCGAGCAA CTTTGCGACC ACCGATCTGG ATGCGGATCG TGGCAAACTG CCGGGCAAAA AACTGCCGCT GGAAGTGCTG AAAGAAATGG AAGCGAACGC GCGTAAAGCC GGTTGCACCC GTGGCTGCCT GATTTGCCTG AGCCATATTA AATGCACCCC GAAAATGAAA AAATTTATCC CGGGTCGTTG CCATACCTAT GAAGGCGATA AAGAAAGCGC GCAGGGCGGC ATTGGC
|
 "
"


